|
|
|
![]()
![]()
![]()
PARTICIONAMIENTO
Introducción
Las bases de datos de gran tamaño plantean grandes retos a los administradores y diseñadores de aplicaciones. Por ejemplo, grande cantidad de datos complican las tareas administrativas y afectan a la disponibilidad de la base de datos. La mayoría de las tareas administrativas deben realizarse en un plazo muy corto, para que afecten lo menos posible el rendimiento de las operaciones efectuadas on line.
A medida que crecen las tablas, las operaciones administrativas como importación y exportación de datos, copias de seguridad, recuperación de datos y desfragmentación de las tablas, deben dividirse manualmente en secciones manejables que encajen en los plazos necesarios.
Por lo general, el gran tamaño de una base de datos es debido a una o más tablas muy grandes, y no a un elevado número de tablas más pequeñas. Por ejemplo, la mayoría de los sistemas de data warehouses y de soporte a la toma de decisiones cuentan con un pocas tablas de eventos de gran tamaño y varias tablas de consulta más pequeñas. Asimismo, si deja de estar disponible un disco que contiene parte de una tabla grande, toda la tabla quedará inaccesible y deberá interrumpirse todo el procesamiento relacionado con esa tabla.
Para facilitar la administración, aumentar la disponibilidad de los datos críticos y mejorar el rendimiento de las consultas y del lenguaje de manipulación de datos (DML), Oracle8 permite dividir las tablas y los índices en particiones, o partes más pequeñas, en función de un rango de claves.
Una tabla o un índice se puede dividir en particiones, o partes más pequeñas. Una parte individual de un objeto dividido de esta manera se denomina partición. Todas las particiones de una tabla o un índice tienen las mismas columnas, desencadenantes y restricciones, pero sus atributos de almacenamiento pueden ser diferentes. Cada partición de una tabla almacena un subconjunto de las filas de la tabla.
Una tabla o un índice dividido en particiones resulta transparente para los usuarios y las aplicaciones. La tabla o el índice se utiliza como si fuera un objeto normal. No es necesario volver a escribir las aplicaciones para aprovechar las ventajas del particionamiento.
De la misma forma, las operaciones de gestión de particiones son instrucciones SQL de fácil uso. Los administradores pueden añadir, dividir, fusionar, modificar o eliminar particiones utilizando comandos sencillos.
La división en particiones mejora la disponibilidad, la capacidad de gestión y el rendimiento en sistemas de data warehouse y de procesamiento de transacciones on line (OLTP). Ya que las particiones funcionan independientemente las unas de las otras, los datos contenidos en una tabla dividida de esta manera están disponibles aunque una o más particiones no lo estén. Las particiones también facilitan la gestión de tablas grandes al dividir las tareas administrativas en otras más pequeñas, que a su vez pueden realizarse en paralelo.
Por último, la división de una tabla o un índice en particiones puede mejorar el rendimiento de las operaciones realizadas con los datos al eliminar las particiones no utilizadas de la fase de ejecución de la operación y permitir la realización de nuevas operaciones en paralelo.
Limites de las particiones
Cada partición de una tabla o un índice está limitada por un rango de valores. Estos límites están determinados por el valor de la clave de partición, es decir la columna o el conjunto de columnas mediante el cual se decide realizar la partición. La clave de partición determina el contenido de cada partición
Cuando se introducen nuevos datos en una tabla dividida en particiones, los límites determinan en qué partición se sitúan; sólo los valores que quedan dentro de los límites de la partición se sitúan en la partición.
Por ejemplo, la tabla VENTAS contiene datos históricos de los cuatro últimos trimestres. Sólo se cambian o se accede frecuentemente a los datos del trimestre actual, y apenas se accede a los restantes trimestres. En este caso se elegiría la columna FECHA_VENTAS como clave de partición.
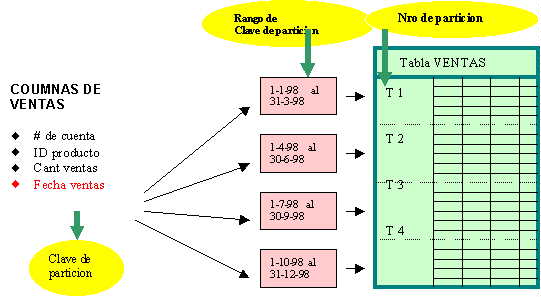
Particionamiento para facilitarla gestión y administración
El particionamiento ofrece un mayor control sobre la ubicación y distribución de los datos de una tabla. Por lo tanto, las tareas de gestión y administración se simplifican bastante. Puesto que las particiones dividen una tabla en partes más pequeñas, la mayoría de las tareas de administración se pueden realizar con mayor rapidez, en paralelo o según sean necesarias.
Cada partición de una tabla o un índice se almacena en un segmento independiente. También se puede almacenar cada partición en un tablespace independiente. El almacenamiento de cada partición en su propio tablespace ofrece las siguientes ventajas:
Los administradores pueden especificar atributos de almacenamiento para cada partición y la posición de la partición en el sistema de archivos del host, aumentando así el nivel de detalle del control con bases de datos muy grandes. Es posible situar las particiones fuera de línea u on line, realizar copias de seguridad de las mismas, y recuperarlas, exportarlas, importarlas y cargarlas individualmente, limitando así el tiempo necesario para realizar las operaciones de gestión. Se puede crear una partición individual de índice para una partición de una tabla, reduciendo así el tiempo necesario para llevar a cabo las operaciones de mantenimiento de índices.
Hay disponibles diversas estrategias locales y globales para índices, y las operaciones efectuadas con las particiones se pueden realizar en paralelo. Las particiones aumentan la disponibilidad al actuar como muro de contención en caso de producirse fallos en los soportes de almacenamiento y las aplicaciones; las aplicaciones que no necesitan los datos contenidos en una partición no disponible continúan ejecutándose sin verse afectadas.
Por ejemplo, la tabla VENTAS divide los datos en cuatro particiones correspondientes a los cuatro trimestres del año. Si el trimestre actual fuese T3, es posible que existiera bastante demanda de los datos contenidos en la partición T3: informes resumidos para soporte a la toma de decisiones, introducción on line, operaciones diarias de carga, etc. La demanda de los datos correspondientes a los otros trimestres podría ser menor. Al colocar cada partición en su propio tablespace, T3 se puede situar aparte en unidades de disco más rápidas. Además, se puede mantener una planificación aparte para realizar copias de seguridad de los datos correspondientes a la misma, ya que sus datos se modifican con mayor frecuencia que los de los otros
trimestres; así, se podrían realizar copias de seguridad de las otras particiones una vez a la semana, y copias de seguridad de T3 a diario.
Administración mejorada
Todas las operaciones de administración se pueden realizar independientemente para cada partición. Las tareas que anteriormente se realizaban de manera secuencial en grandes tablas se dividen ahora automáticamente y pueden realizarse de forma concurrente o en paralelo.
Particionamiento para aumentar la disponibilidad
El particionamiento ofrece mayor control sobre la ubicación de los datos, permitiendo distribuirlos en varios dispositivos para mejorar la carga de trabajo y aumentar la disponibilidad de los mismos. Si una unidad de disco experimenta un fallo y esa unidad contiene datos de una sola partición, todas las demás particiones de la tabla seguirán estando disponibles para consultas y operaciones DML.
Además, operaciones de administración tales como la defragmentación de tablas no se traducen en la indisponibilidad de toda la tabla, ya que el trabajo realizado en otras particiones puede efectuarse concurrentemente.
El particionamiento proporciona una protección contra fallos de disco y un aislamiento respecto de las operaciones administrativas concurrentes
Particiones y distribución de datos en discos
Las particiones y la distribución de datos en discos a través del sistema operativo actúan recíprocamente de manera transparente. Para aplicaciones que precisan el más alto rendimiento, la distribución de datos en disco a través del sistema operativo puede aumentar el rendimiento de tablas tanto divididas como no divididas en particiones. Si bien esta distribución tambien puede afectar la disponibilidad de las aplicaciones críticas.
Las particiones ofrecen un mayor grado de control sobre los datos distribuidos en varios dispositivos. Por lo tanto, las tablas divididas en particiones permiten gestionar las necesidades de disponibilidad junto con las necesidades de rendimiento.
Por ejemplo: supongamos que disponemos de ocho unidades de disco y se ha configurado una tabla en cuatro particiones. En la siguiente figura se muestra cómo la distribución de cada partición entre un grupo distinto de discos aporta la mayor disponibilidad, mientras que la distribución de cada partición entre todos los discos ofrece el mayor rendimiento.
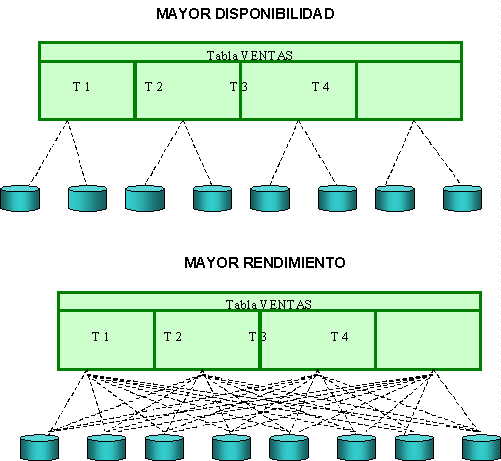
Hay que considerar el compromiso entre disponibilidad y rendimiento al utilizar juntas la distribución de datos en discos y el particionamiento. En sistemas críticos, la disponibilidad debe ser la principal consideración. En el ejemplo anterior, si sólo se utilizan con frecuencia los datos correspondientes al trimestre actual, podrían distribuirse en algunos dispositivos, cuanto menor sea el número de dispositivos, mayor será la disponibilidad. Si las otras particiones de la tabla no se utilizan con frecuencia, podrían distribuirse entre la mayoría de los discos, en cuyo caso el reducido número de consultas que accediesen a las mismas se realizarían con mayor rapidez.
Aumento del rendimiento
El particionamiento aumenta el rendimiento al distribuir los datos entre varios dispositivos. Se puede controlar el dispositivo en el que reside una partición y, por lo tanto, colocar los datos críticos o aquéllos a los que se accede con mayor frecuencia en unidades de disco más rápidas.
Se han añadido a Oracle8 algunas nuevas operaciones en paralelo que funcionan conjuntamente con el particionamiento, como ser: DML en paralelo y exploraciones de índices en paralelo. La arquitectura de consultas en paralelo de Oracle, no precisa el particionamiento y pues funciona independientemente del sistema de particionamiento. Además, el particionamiento permite que el optimizador de consultas elimine los datos innecesarios del plan de ejecución de consultas.
Por ejemplo, si existen varias regiones de ventas y rara vez se utilizan los datos entre las regiones, una tabla de introducción de órdenes de venta podría dividirse en particiones por región para dividir la carga entre varios discos.
Entonces se podría decir que el particionamiento aporta compensación de carga, distribución de datos, nuevas operaciones en paralelo y una mejor optimización de las consultas
Este enfoque compensa la carga de los dispositivos de E/S y aumenta el rendimiento de las consultas. Puesto que la mayoría de las consultas solicitan datos de una sola región, el optimizador de consultas puede eliminar todas las demás particiones. Si la tabla no estuviera dividida en particiones, es posible que lel optimizador de consulta tuviera que realizar una exploración de toda la tabla o de índices para obtener los datos contenidos en una sola partición. Una exploración completa de una única partición con E/S multibloque es mucho más eficiente que una exploración completa de toda la tabla o de los índices. Puesto que el optimizador es consciente de las particiones de una tabla, puede tomar decisiones más inteligentes al ejecutar las consultas.
Aumento del rendimiento de las combinaciones
El particionamiento también puede aumentar el rendimiento de determinadas operaciones de combinación. Si siempre se combinan varias tablas con una clave común y a menudo se seleccionan subconjuntos previsibles de los datos, el particionamiento puede agilizar esta operación.
Por ejemplo, podría existir el esquema de Personal mostrado a continuación.
En el gráfico anterior, la consulta precisa la combinación de la información contenida en siete tablas relativamente pequeñas. El plan de ejecución para esta consulta puede necesitar una exploración de tabla completa en todas las tablas antes de realizarse las operaciones de combinación, dependiendo del tamaño de las tablas. Aunque las tablas fuesen pequeñas, la consulta podría agilizarse dividiendo los datos en la condición de combinación.
En el caso de consultas que siempre buscan un conjunto común de valores de columna en varias tablas, el particionamiento puede aumentar el rendimiento. En el ejemplo anterior, una aplicación de recursos humanos siempre selecciona la información de los empleados para todo un departamento. En la figura siguiente puede verse cómo el particionamiento puede agilizar la ejecución de la consulta al eliminar las particiones innecesarias y realizar una exploración sólo de la partición solicitada en cada tabla.
En el gráfico anterior se muestra que es necesario solo una exploración de una partición para cada una de las tablas de la combinación de siete vías. Esto elimina la mayor parte de los datos en cada una de las tablas y aumentar significativamente el rendimiento de la instrucción.
La división en rangos aporta los máximos beneficios
La clave de partición divide la tabla en uno o más rangos de valores para cada partición. Es lo que se denomina comúnmente división en rangos. Con la división en rangos, las mejores claves de partición son las columnas de fecha, clave principal o clave foránea. Hay también otros esquemas de particionamiento, pero su objetivo es distribuir de manera uniforme los datos entre las particiones de una tabla.
Oracle8 no necesita que las particiones de una tabla se distribuyan uniformemente para aportar un alto rendimiento. La división en rangos garantiza la independencia de las particiones, ya que sólo se pueden situar en una determinada partición los valores comprendidos en los rangos especificados. La independencia de las particiones es necesaria para conseguir el más alto nivel de rendimiento, disponibilidad y facilidad de gestión.
Se puede controlar el tiempo necesario para realizar todas las operaciones de administración creando más particiones para una tabla y dividiendo o fusionando particiones existentes.
Oracle8 ofrece comandos de fácil uso para crear, mantener y manipular particiones de tablas. La mayoría de las operaciones de base de datos se realizan de forma óptima tanto en una tabla dividida en particiones uniformes como en una tabla desigual. Para eso, apenas se necesita otro esquema de particionamiento que no sea la división en rangos.
Con la división en rangos se obtiene la ventaja de la eliminación de las particiones no utilizadas de los planes de ejecución de consultas. Ya que las particiones sólo contienen los datos comprendidos en un determinado rango, el optimizador de consultas puede eliminar las particiones que no contengan los datos solicitados por la consulta realizada. Esto se traduce en mejores planes de ejecución y en consultas más rápidas. La división circular en particiones no puede garantizar que una partición cualquiera pueda eliminarse de una consulta, por lo que todas las particiones deben participar en cada consulta. Esto no sólo reduce el rendimiento de las consultas, sino que compromete asimismo la disponibilidad.
![]()
![]()
![]()